 by
by Hashing is a technique used to search an specific item in large group of items. Hashing uses hash table to perform search in an constant O(1) time. Hashing uses hash functions to fill items in a hash table. To search, each key is passed into the same hash function which computes an index which provides the corresponding value location.
Let’s have a look at the ideal hash table.
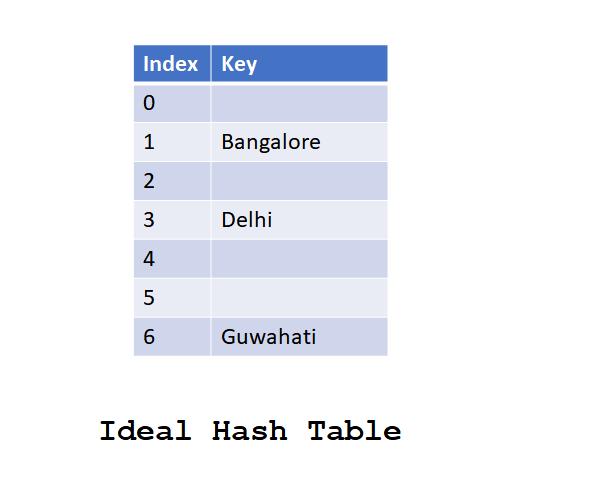
Hashing Methodology
Hashing method has following key constituents.
Hash Table
A Hash table in Hashing is the data structure which stores all the key value pairs. Hash functions are used to insert values in the hash table. A good hash table must have uniformly distributed values.
Hash Function
A Hash function in Hashing is a function which converts the input data arbitrary range to a fixed range defined by the Hash Table. The value computed by the hash function is called the hashes or hash values of key “K”.
Example:
- Modulo (%) of key with Hash table size.
- Last 5 digits of a mobile number.
Properties of Good Hash Function
A Good hash function needs to have following properties
- It should compute hash code fast.
- Hash codes generated by hash functions should be uniformly distributed across the hash table.
- Hash function should avoid generating same hash code for different keys. In real world problems, this is very hard to achieve. This scenario where multiple keys hash codes are same is called Collision.
Collision Resolution
A collision in hashing occurs when couple of keys have same hash codes. To handle such scenarios following collision resolution techniques can be used:
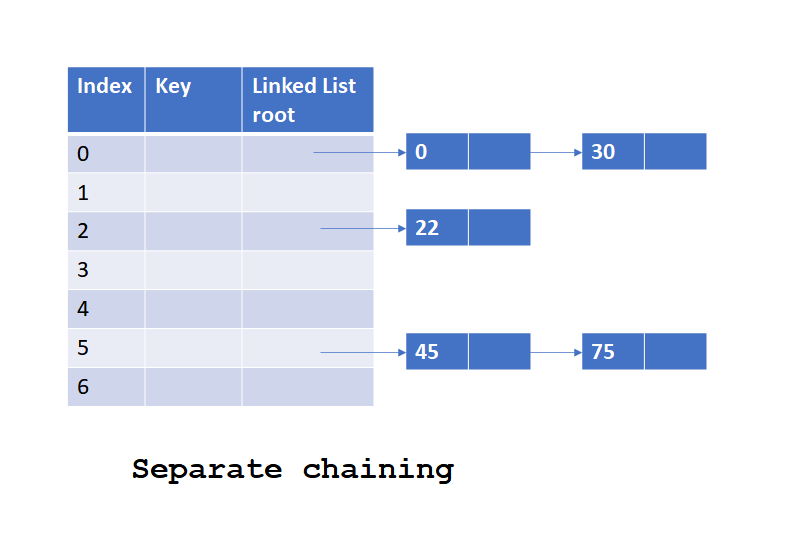
Separate Chaining
This is one of the most common collision resolution technique which uses a linked list to store all the keys having same hash code. In this case, each place in Hash table can be a linked list.
- In separate chaining, each key is inserted into a linked list present at the hash code location in hash table.
- While searching for a key,
- Linked list is identified using the hash code generated by the hash function for the key.
- Key is searched in the linked list by traversing through it.
Let’s have a look into the below diagram to understand how separate chaining stores and searches the data.
Pros
- Easy implementation.
- Good enough for problems where collision are rare and almost uniformly distributed.
Cons
- Extra memory is used for linked list implementation.
- Not good for scenarios where collisions are quite frequent as linked list traversal would affect the search time.
- Not good for scenarios where collisions are clustered in hash table.
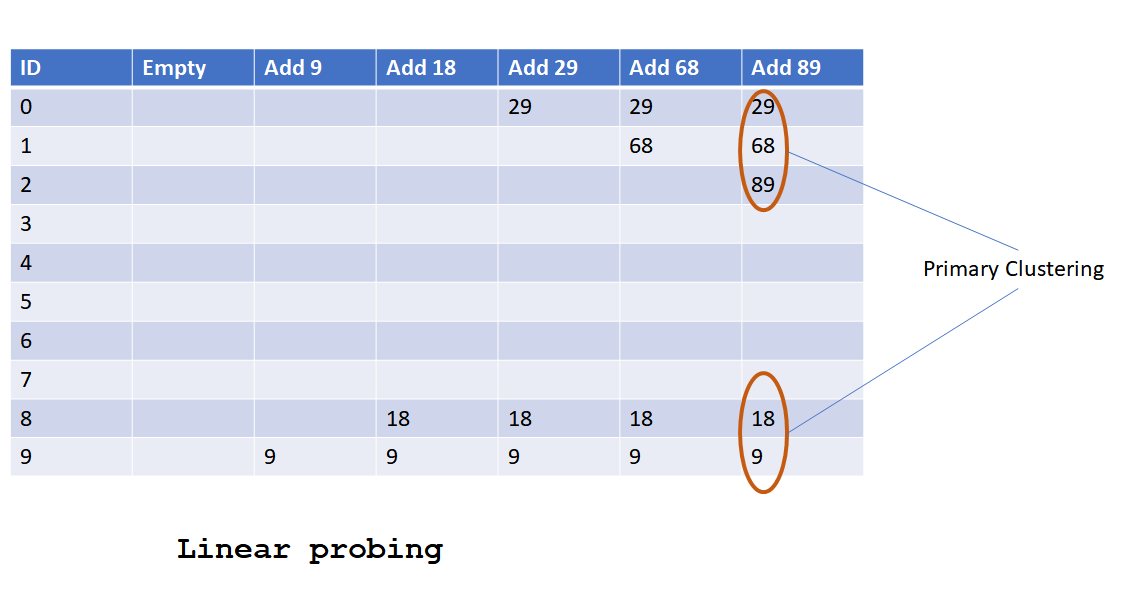
Linear Probing/Open Addressing
In this collision resolution technique of hashing, all keys are stored in the hash table. In this method,
- To insert a key if the computed hash value location in hash table is
- Unoccupied then save the key in this position.
- Occupied then next address is find out by moving one place at a time until an unoccupied slot is found and key us saved.
- To search a key, computed hash value location is compared. If it
- Matches then return the value.
- Didn’t match then next address key is compared by moving one place at a time until key is found, or unoccupied slot is encountered.
Let’s look into below diagram to understand how linear probing works.
Pros
- No extra memory needed.
- Easy implementation.
- Fast collision resolution.
- Good for cases when collision is quite rare and uniformly distributed in hash table.
Cons
- For colliding keys, it does a linear search which can slow down the search.
- Not good for cases where collisions are quite frequent and clustered. In case of clustered hash codes, keys can be stored far away from the hash code location which might slow the searching. This problem is known as Primary Clustering issue of Linear probing.
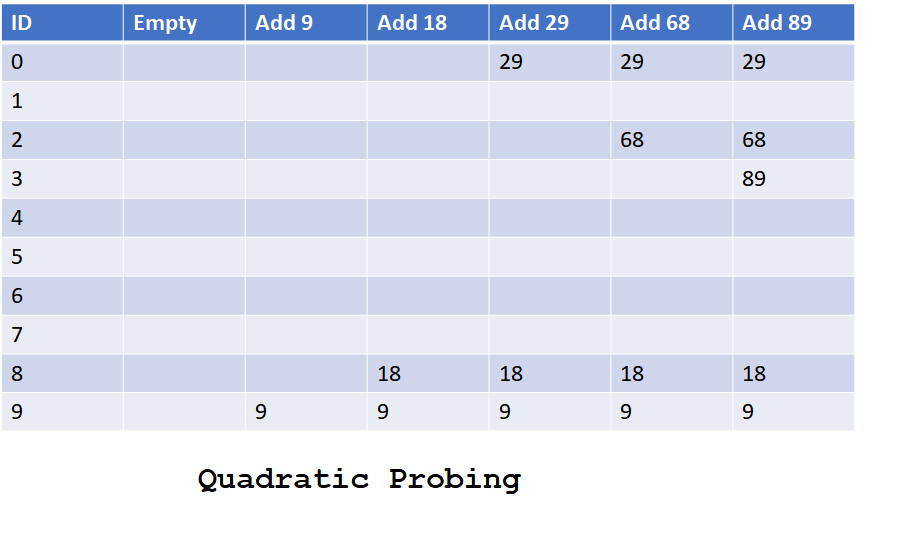
Quadratic Probing
In this collision resolution technique of hashing, all keys are stored in the hash table. In this method,
- To insert a key if the computed hash value location in hash table is
- Unoccupied then save the key in this position.
- Occupied then next address is calculated by adding successive polynomial value to the hash code at a time until an unoccupied slot is found, and key is saved.
For eg: hash_code + 12, hash_code + 22, hash_code + 32 …
- To search a key, computed hash value location is compared. If it
- Matches then return the value.
- Didn’t match then next address is calculated by adding successive polynomial value to the hash code at a time until an unoccupied slot is found and key us saved.
For eg: hash_code + 12, hash_code + 22, hash_code + 32 …
until key is found, or unoccupied slot is encountered.
Let’s look into below diagram to understand how quadratic probing works.
Pros
- No extra memory needed.
- Easy implementation.
- Fast collision resolution.
- Good for cases when collision is quite rare and uniformly distributed in hash table.
- It handles the primary clustering issues observed by Linear probing method.
Cons
- For colliding keys, it does a linear search which can slow down the search.
- Not good for cases where collisions are quite frequent and clustered.
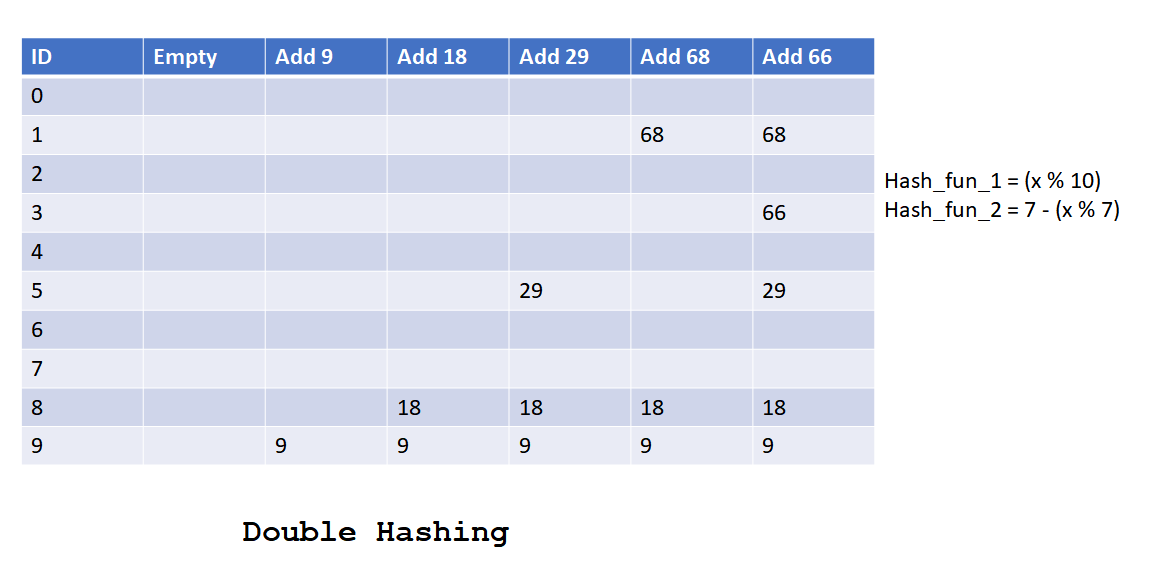
Double Hashing
In this collision resolution technique of hashing, all keys are stored in the hash table. In this method,
- To insert a key if the computed hash value location in hash table is
- Unoccupied then save the key in this position.
- Occupied then next address is find out by using a second hash function multiplied by the step until an unoccupied slot is found.
for eg: hash_fun1 + hash_fun2 * 1, hash_fun1 + hash_fun2 * 2, hash_fun1 + hash_fun2 * 3 ..
- To search a key, computed hash value location is compared. If it
- Matches then return the value.
- Didn’t match then next address is find out by using a second hash function multiplied by the step
for eg: hash_fun1 + hash_fun2 * 1, hash_fun1 + hash_fun2 * 2, hash_fun1 + hash_fun2 * 3 ..
until key is found, or unoccupied slot is encountered.
Let’s look into the below diagram to understand how double hashing works.
Pros
- No extra memory needed.
- Fast collision resolution.
- Handles the clustered hash code collision efficiently.
Cons
- For colliding keys, second hash code calculation which might slow down the search.
- Might be a chance of running out of places to save keys even hash table is empty due to second hash function not covering all possible locations.
- Generally slower than Quadratic Probing method.
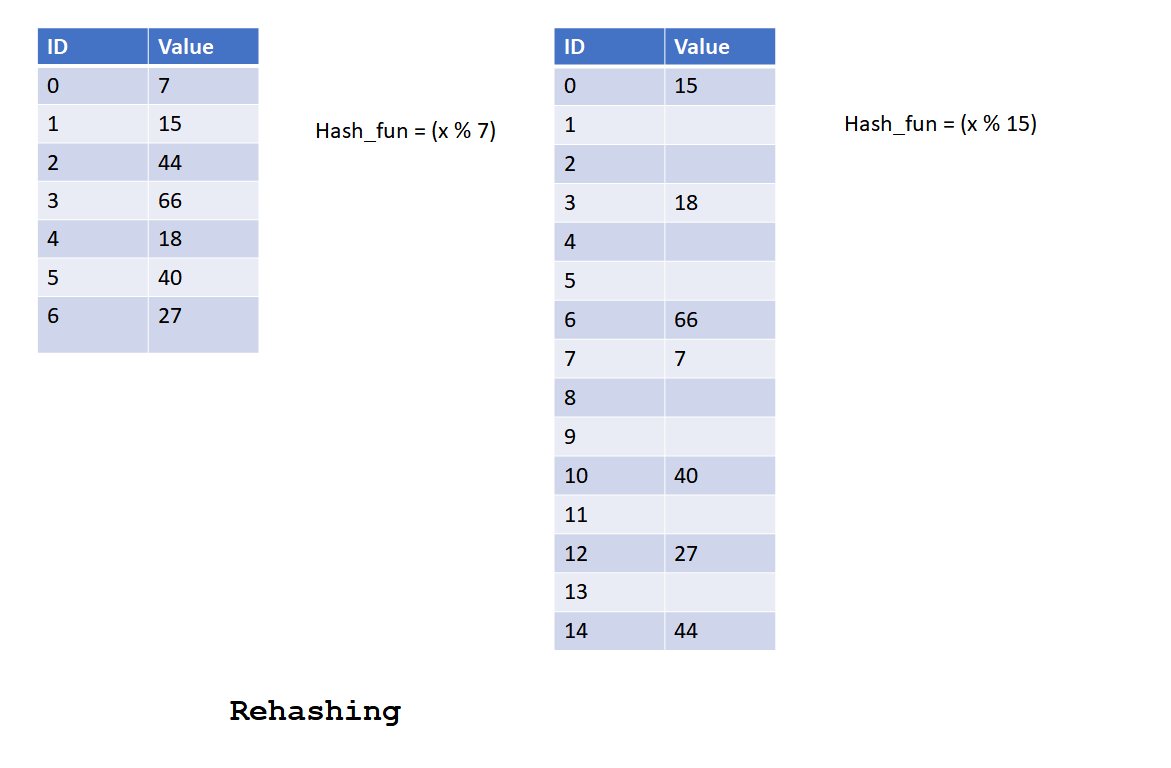
Rehashing
Percentage of entries occupied in hash table is known as load factor of a hash table. For best performance, load factor of a hash table should remain below 60 %. Impact of high load factor on hashing is as follows:
- Inserting an element can be time taking as very less places are available and finding those would be time consuming.
- Searching for a key would be slower as collisions might increase.
To solve this problem, a new hash table is created with double the size of current hash table and entire data from the original hash table copied into new hash table by calculating new hash value.
This operation is called Rehashing.
Let’s look into below diagram to understand how rehashing can improve the insertion/searching operation time.
Pros
- Once rehashing completes, insertion/searching performance improves drastically.
- New hash table has fewer collisions compared to original hash table.
Cons
It’s a costly operation and might take long time to push all data into new table.